
Кадр из мультфильма «Раз горох, два горох», 1981, Союзмультфильм
Сбор исходных данных встречается во многих задачах, связанных с аналитикой. Веб тоже нередко выступает источником. Вероятность попасть на полностью готовый и причесанный источник почти близка к нулю. Всегда приходится что-то делать, чтобы эти данные получить и привести в порядок. Ободряет то, что если в браузере видна нужная информация, то тем или иным способом ее можно оттуда выцарапать. В самом худшем случае — перефотографировать.
Ниже три непридуманные истории, объединенные одной целью — достать информацию из открытого источника. Весь код написан «на салфетке», имеет сугубо иллюстративный и развлекательный характер.
Является продолжением серии предыдущих публикаций на habr.
История 1
Надо покрутить информацию по выплаченным субсидиям. Вот простенький и легкий сайт. Беглое изучение показывает, что разработчики постарались, но забыли одну важную штуку — кнопочку «выгрузить в excel». Сознательно считаем, что они забыли или не успели. Смотрим дальше. Это JS, логика на стороне сервера, на клиента приезжает html со сверстанным фрагментом таблицы. 1366 страниц.
Что там было на курсах? Загрузить страницу по урлу, спозиционировать по тегу и распарсить таблицу? Не выйдет… Нужна эмуляция событий, нужен робот.
Перематываем время вперед и переходим к ответу.

Готовим окружение
- Качаем Selenium 3.x. (4-ка пока не заводится). Берем selenium-server-standalone-x.x.x с сайта архива сборок selenium-release.storage.
- Качаем RSelenium с CRAN.
- Качаем WebDriver под установленные версии браузеров, кладем в PATH (проще и лучше рядом с сервером, поскольку драйвера зависят от версий браузеров).
- Запускаем Selenium Server из cmd командой
java -jar selenium-server-standalone-3.141.59.jar.
Ищем точку для удара
Открываем инструменты разработчка в хроме.
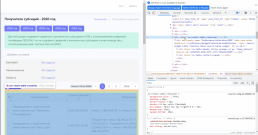
Делаем пробные запросы, смотрим ответы, помечаем маркером.
page_url <- "https://subsidies.qoldau.kz/ru/subsidies/recipients?Year=2020"
rvest::read_html(page_url) %>%
html_nodes(xpath = "//*[@class = 'sw-result-table-container']") %>%
html_table()
rvest::read_html(page_url) %>%
html_nodes(xpath = "//*[@class = 'page-link' and @aria-label]")Спускаем «механического пса»
Код:
library(tidyverse)
library(RSelenium)
library(rvest)
library(iterators)
library(foreach)
# стартанули страницу
remDrv$navigate("https://subsidies.qoldau.kz/ru/subsidies/recipients?Year=2020")
lst <- foreach(it = iter(1:1366, .combine = NULL)) %do% {
# локализуем элемент с таблицей
tab_elem <- remDrv$findElement(using = "xpath", value = "//*[@class = 'sw-table-content-wrapper']")
df <- read_html(tab_elem$getElementAttribute('innerHTML')[[1]]) %>%
html_table() %>%
# забираем тело таблицы
.[[1]]
# локализуем элемент "дальше"
# тут выборка по русскому значению тега срабатывает, этим и воспользуемся
next_elem <- remDrv$findElements(using = "xpath", value = "//*[@class = 'page-link' and @aria-label = 'Следующая страница']")[[1]]
remDrv$mouseMoveToLocation(webElement = next_elem)
next_elem$click()
df
}Получаем data.frame, остальное — дело техники.
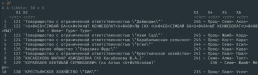
История 2
Отрываем шампанское
Надо решить социологические вопросы. Выборы в Германии, 2017 год. После долгих мучений найден отличный сайт, прекрасный js интерактив, есть вся информация, фейрверк с хлопушками. Супер! Сейчас все быстренько накраулим.
И тут подкрадывается ложка дегтя. Интерактивный leaflet с детализацией по более чем 5000 объектам. Рука с поводком от робота тихоньку прячется в карман. Хочется пойти на улицу и посмотреть на школьников, идущих с уроков. Выпить чашку кофе. И не видеть этот сайт, который минуту назад казался замечательной находкой.
Осторожно, двери закрываются. Мы успели в вагон или нет? В какой реальности существуем дальше? Там где сайт выкинут и пошли искать дальше? Или там, где мы достали все, что хотели?
Оставим первую ветку сценаристам. Может там все закончилось очень хорошо и этот провал привел потом, далеко потом, к огромному успеху. Пойдем по второй ветке.
Ищем внизу
Открываем инструменты разработчика. Смотрим инфообмен. Кликаем на город — да тут приезжает json. С чем? Да с результатами выборов. Вот же оно! Загвоздка в адресации этих результатов, как бы понять что к чему?
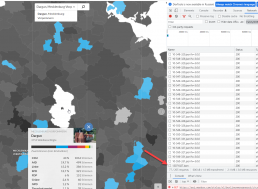
Ищем наверху
Делаем второй заход сверху. Ага, тайловая карта… и какие-то json прилетают. Что там? Да это же список всех точек по которым есть детальная информация… Так-так, сверим номерки. Все, связка найдена, тут лежат как раз те самые номера по которым запрашиваются json с детализацией.
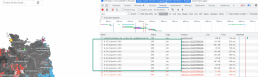
Проводим операцию
Достаем молоток и паяльник, 15 минут кодирования, 1 минута работы. Результат на столе.
Собираем результаты выборов
library(tidyverse)
library(glue)
# путем просмотра https://interaktiv.morgenpost.de/gemeindekarte-bundestagswahl-2017/
# наблюдаем список подгружаемых тайлов, формируем его руками
tiles_df <- tidyr::expand_grid(i = 32:34, j = 20:22) %>%
mutate(url = glue("https://interaktiv.morgenpost.de/gewinner_btw2017/grid/6-{i}-{j}.json?v=3.0.0"))
# Шаг 1. собираем список всех городов
loadTile <- function(url){
resp <- httr::GET(url)
bind_rows(httr::content(resp)[["data"]])
}
job_df <- tiles_df$url %>%
purrr::map_dfr(loadTile)
# Шаг 2. Собираем данные по каждому городу
loadTown <- function(id){
resp <- glue("https://interaktiv.morgenpost.de/",
"gemeindekarte-bundestagswahl-2017/data/",
"jsons/{id}.json") %>%
httr::GET()
bind_rows(httr::content(resp)) %>%
mutate(AGS = id)
}
town_df <- job_df %>%
slice(1:10) %>%
pull(AGS) %>%
purrr::map_dfr(loadTown)
Неожиданный третий сценарий. Прочитать содержание сайта на немецком до конца. Внизу увидеть ссылки на источники информации, примененные при создании сайта. Сходить по ссылкам и забрать таблички. Узнать чуть позже, что таблички не учитывают всех обновлений в делении.
История 3
Национальная электронная библиотека. Книжные памятники. Книга «Толкование на Апокалипсис», 1625 год. Естественно, что можно только цифровую копию глядеть, в книжных магазинах не найти, даже в букинистических. Уникальная возможность!
Нужно для работы. Единственно, что пользоваться только просмотром с экрана через некоторое время становится очень мучительно. И никаких закладок не поставить. Ничего распечатать нормально невозможно, вся страница сжимается в вертикальную полоску. Фотографировать экран, печатать и склеивать скотчем? И так все нужные страницы? После серии экспериментов становится ясно, что можно и от руки с экрана переписывать. Примерно также продуктивно. Беда в том, что и большой экран 34″, повернутый по вертикали, тоже не особо помогает — с близкого расстояния обозреть всю страницу почти невозможно.
Сохранить изображение тоже невозможно, сохраняется preview в низком разрешении, что критично для понимания текста. При беглом взгляде становится понятно, что это тайловый набор и страницы как таковой вроде и не существует. Есть просто различные фрагменты, собираемые браузером воедино.
Приехали?
Открываем инструменты разработчика в хроме, начинаем изучать сетевой обмен. Изучение нескольких страниц дает примерное понимание внутренней механики и способов сборки тайлов в страницу. Разный зум, различная сетка.
Можно попробовать взять в руки инструменты. Из хитростей — монтаж тайлов в единую картину с помощью ImageMagick. Минута работы и на руках у нас нужная страницы в максимальном разрешении в виде единого графического файла.
scrap_one_page.R
library(tidyverse)
library(magrittr)
library(httr)
library(rvest)
library(stringi)
library(glue)
library(jsonlite)
library(furrr)
library(magick)
n_cores <- parallel::detectCores() - 1
# директории разного типа содержат тайлы 256x256 разных увеличения
# 10 -> 11 -> 12 (max)
# базовый url страницы
base_url <- "https://kp.rusneb.ru/tiles/5fd08afffc8ed229eaf02309_files"
# 1. генерируем фиктивную сетку
grid_df <- expand_grid(y = 0:12, x = 0:12) %>%
mutate(img_name = glue("{x}_{y}.jpeg"),
url = glue("{base_url}/11/{img_name}"),
fname = here::here("page", img_name)
)
# 2. загружаем в многопотоке
# plan(multisession, workers = n_cores)
plan(sequential)
processTile <- function(url){
purrr::possibly(image_read, otherwise = NULL)(url)
}
img_lst <- grid_df %$%
future_map(url, processTile)
plan(sequential)
tiles_df <- grid_df %>%
mutate(img = !!img_lst) %>%
drop_na(img)
# 3. склеиваем тайлы (монтаж)
image_obj <- purrr::lift_dl(c)(tiles_df$img)
tile_str <- tiles_df %$%
glue("{n_distinct(x)}x{n_distinct(y)}")
res <- image_montage(image_obj, geometry = "256x256+0+0", tile = tile_str,
bg = 'black', gravity = "North")
# 4. сохраняем страницу
image_write(res, path = here::here("page", "page.jpg"), format = "jpg")