Как-то так получилось, что в 2020 году возник всплеск интереса к тематике Process Mining. Не исключено, что новая реальность удаленного режима потребовала более пристальной оценки эффективности технологических и бизнес-процессов. Это же как с кривыми и косыми деревянными рамами. Сквозит из всех щелей, а счетчик накручивает мегаватты на обогрев.
В целом, видны несколько популярных запросов по применению технологии process mining:
-
- хочется что-то улучшить, но кроме модного слова больше ничего не слышали;
- получить или сэкономить «живые деньги» путем оптимизации классического процесса «order-to-cash» и ему подобных;
- системный аудит всего и вся собственной командой аудиторов;
- построение операционной аналитики и мониторинга на основе показателей процессов, а не ИТ метрик.
В 99% случаев начинают читать Gartner/Forrester и попадают на 4-ку вендоров (Celonis/Minit/Software AG/UiPath), которые как-то присутствуют в России. И до того, как начать получать какую-либо выгоду, тут же получают немаленький ценник за лицензии и последующую ежегодную поддержку. При этом экономическое обоснование шито белыми нитками.
А действительно ли нужно идти таким путем? Особенно, когда задачи и цели не до конца понятны самим постановщикам. Не стоит забывать, что вендоры требуют специально подготовленный лог событий, а его подготовка может вылиться в головную боль и многие месяцы интеграционной работы в классическом enterprise ландшафте.
Является продолжением предыдущих публикаций.
Преамбула
Так ли уж технологии process mining недоступны простым смертным и все страшно и дорого?
Нет, нет и еще раз нет. 90% задач в продуктиве и 100% задач на исследовательском этапе могут быть закрыты open-source инструментами. Экосистема R позволяет их решать практически в полном объеме. Причем даже аудиторы и сотрудники HR службы могут освоить инструменты и эффективно их применять в своей повседневной деятельности. Что уж говорить о разработчиках и аналитиках.
И когда задача будет ясна, выгода от применения коммерческих инструментов будет обоснована, вот тогда и можно задуматься о приобретении лицензий на коммерческое специализированое ПО. Или же наоборот, об экономии средств и сокращении нецелевых трат.
Ниже несколько аргументов и иллюстраций в стиле «беседа в лифте от 1-го до 30-го этажа», как именно используется R для применения технологий process mining во внутренних службах аудита бизнес-процессов.
Весь последующий текст без купюр и с иллюстрациями доступен в виде презентации.
Актуальность
В задачах аудита бизнес-процессов, как правило, требуется выполнение следующих требований:
-
- скорость (= деньги) проведения аудита;
- возможность самостоятельного подключения любых источников данных;
- возможность самостоятельного проведения любой сложности трансформации данных;
- возможность быстрого проведения аналитических итераций;
- возможность повторного проведения аналитики с получением идентичных результатов;
- представление результатов аудита красивом виде и в различных форматах.
Типичный сценарий проведения аудита процессов выглядит следующим образом:
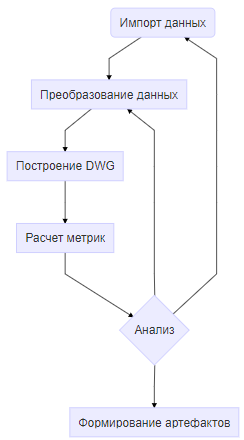
Задача аудита по своей сути является разовой и уникальной. Новые источники данных, новая постановка задачи, новые инсайты. Практика показала, что использование коробочных process-mining решений для задач аудита не имеет особых преимуществ перед способами анализа процессов средствами data-science стека.
Основные причины кроются в том, что:
-
- решениям требуется лог событий в жестко заданном формате, ETL нужно делать где-нибудь вовне;
- парадигма проведения аналитики только мышкой заканчивается на 2-м или 3-м шаге, когда все равно требуется открывать капот и программировать сложные метрики и сложные формулы на встроенном «вендоро-зависимом» языке;
- «аналитика мышкой» требует проведения стека ручных операций при повторных вычислениях;
- лицензии стоят очень дорого.
Альтернативный вариант
Задача process-mining по своей сути ничем не отличается от классических задач анализа данных. Для ее решения можно успешно использовать стек data science инструментов, в частности, стек, построенный open-source на экосистеме R Tidyverse. Сам инструмент обладает широким спектром возможностей, доступ к которым появляется при подключении тех или иных open-source пакетов. Пакетов на настоящий момент существует более 10 тысяч, они активно развиваются. Но, поскольку задача process-mining достаточно ограничена, далее мы будем упоминать только пакеты, которые будут часто использоваться в задачах process mining office (PMO).
Обзор технических возможностей и способов решения типовых операций в контексте PMO будет подкрепляться компактными фрагментами кода. Важно учитывать, что в data science принято придерживаться концепции «воспроизводимых вычислений», т.е. применение технологий и методологий по автоматическому (скрипт) получению идентичных результатов, выполняемых на разными людьми на разных машинах в разное время.
Важно то, что в задаче process-mining программирования не избежать в принципе, как бы этого ни хотелось. В случае с data science стеком это совершенно не критично, поскольку для аналитических кейсов PMO конструкции языка общего назначения R и пакетов tidyverse максимально приближены к человеческому языку и набор типовых операций ничуть не сложнее работы в Excel.
Краткое резюме по применению R для задач process mining:
-
- дешево (open-source);
- быстро (как время работы аналитика, так и время вычислений);
- компактно (данные в 10-100 млн строк можно «крутить» на обычном ноутбуке);
- воспроизводимо (все действия описываются в виде кода, поддерживается методология «воспроизводимых вычислений»);
- функционально (в целом, экосистема R содержит > 10 тыс. пакетов, включая импорт/экспорт, процессинг, алгоритмы, визуализацию, разработку web АРМ, …).
Импорт данных
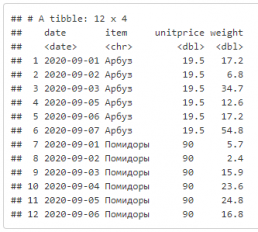
Импорт из csv, команда и получаемая таблица:
read_csv("./data/pmo/pmo_sales.csv")
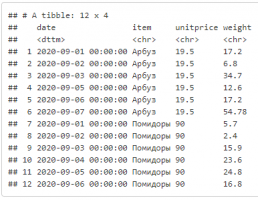
Импорт из xlsx, команда и получаемая таблица:
read_excel("./data/pmo/pmo_sales.xlsx", sheet = "Данные здесь")
Импорт данных из БД: MS SQL, PostgreS, Oracle, MySQL, Access, Redis, Clickhouse,… Детально можно прочесть «Databases using R» (https://db.rstudio.com/)
Преобразование данных
Самые базовые действия (глаголы) на примере данных о продажах. Детально можно ознакомиться здесь:
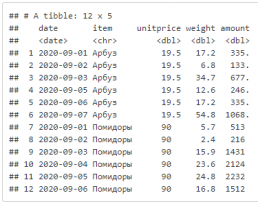
Глагол mutate — создание колонки.
df <- read_csv("./data/pmo/pmo_sales.csv") %>%
# считаем выручку по позициям
mutate(amount = unitprice * weight)
df
Глагол group_by — группировка по колонкам, глагол summarise — расчет подытога.
# считаем выручку по товарам df %>% group_by(item) %>% summarise(sum(weight), sum(amount))

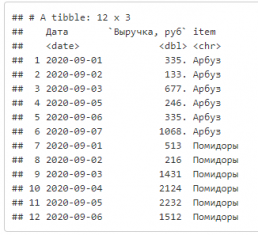
Глагол select — выбор и переименование колонок.
df %>%
select("Дата" = date, "Выручка, руб" = amount, item)
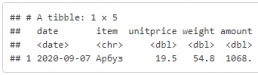
Глагол filter — выбор строк по условию.
df %>% filter(amount > 1000, item == "Арбуз")
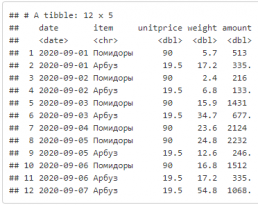
Глагол arrange — сортировка строк по колонкам.
df %>% arrange(date, desc(amount))
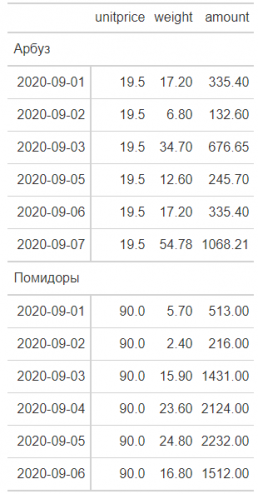
Пример форматного вывода в отчет
df %>% group_by(item) %>% gt(rowname_col = "date")
Посмотрим графически на продажи
gp <- ggplot(df, aes(date, amount, color = item, fill = item)) + geom_point(size = 4, shape = 19, alpha = 0.7) + geom_line(lwd = 1.1) + scale_x_date(date_breaks = "1 day", date_minor_breaks = "1 day", date_labels = "%d") + scale_y_continuous(breaks = scales::pretty_breaks(10)) + ggthemes::scale_color_tableau() + ggthemes::scale_fill_tableau() + theme_bw() gp
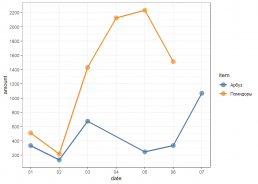
А можно разложить по фасетам
gp + facet_wrap(~item) + geom_area(alpha = 0.3)
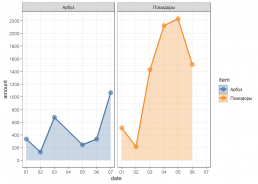
Примеры преобразований на основе лога событий
Импорт лога
df <- read_csv("./data/pmo/pmo_school.csv")
df
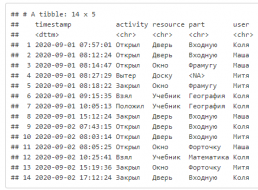
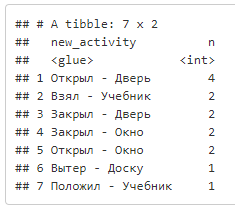
В ходе анализа решили сформировать новое поле активности на основе activity и resourse и посчитать число вхождений
df %>%
mutate(new_activity = glue("{activity} - {resource}")) %>%
count(new_activity, sort = TRUE)
Какая активность была последней и в какой час она происходила?
df %>% mutate(hr = hour(timestamp), date = as_date(timestamp)) %>% group_by(date) %>% # оставляем самое последнее действие filter(timestamp == max(timestamp)) %>% ungroup() %>% select(date, hr, everything(), -timestamp, -part)

Пример построения DWG графа с применением функций пакета bupaR (https://www.bupar.net)
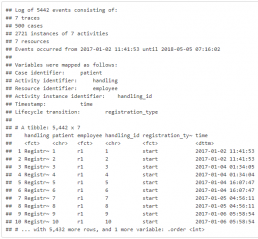
Событийный лог взаимодействия с пациентами.
patients
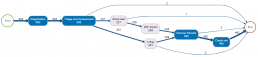
Карта процесса
patients %>% process_map()
Метрики производительности процесса
patients %>% process_map(performance(median, "days"))

P.S.
- Приведенные методы являются, естественно, существеным упрощением полной теории. Но это упрощение вызвано простотой самих процессов в enterprise. Классический бизнес даже близко не приближается к сложности коллайдера.
- Небольшой демонстрационный код по этой тематике был опубликован ранее, «Бизнес-процессы в enterprise компаниях: домыслы и реальность. Проливаем свет с помощью R».
- Для более детального погружения в тематику process mining даю отсылку к отправной точке, труду Wil M. P. van der Aalst «Process Mining: Data Science in Action». Лекции, статьи, книги и т.д. можно далее искать самостоятельно, если тема заинтересует.
Предыдущая публикация — «Пакеты-пакеты-пакеты… Насколько эффективно вы используете R?».