
Избушка, Olga Kolopetko. https://illustrators.ru/illustrations/1474142
Повсеместная цифровизация не только в телевизоре. Она теперь повсюду нас окружает, на работе и не только. Типичным представителем являются трекеры действий (системы Сервис Деск, проектные системы, документообороты и пр.). Общей болевой точкой всех этих систем являются сложная объектная и процессная модель и фокус на поддержку операционного обслуживания. Шаг влево или вправо в попытках понять всю картину целиком повергает аналитиков в уныние и порождает безуспешные проекты на многие месяцы. А вопрос этот висит в воздухе, в том или ином виде, почти ежедневно.
Ниже покажу один из возможных подходов по решению подобных задач средствами DS «за час» и «один экран кода». ИТ курсов на несколько месяцев появилось множество, но даже для начинающих подход от конца, когда показываешь решение насущной задачи, а потом раскладываешь его на кубики — куда эффективнее.
Для примера возьмем Jira, как часто используемую в среде разработчиков, обладающую богатым функционалом, длительной историей и хорошим API.
Все предыдущие публикации на habr.
Постановка задачи
Возьмем простейшую задачку.
Есть проект, в нем несколько потоков (бэк, фронт, аналитика, …). Каждый спринт необходимо формировать закрывающую сводку по потраченному времени в разрезе разработчиков, задач и потоков.
Как будем решать?
Важно понимать, что все трекинговые системы построены примерно идентично. База с кучей перелинкованых табличек. Есть отдельные аккумулирующие счетчики, актуальные на «здесь и сейчас». Нет никаких полноценных сущностей, запросов на дату и пр. Надо все реконструировать самим. Примерно по такой последовательности (ключевые слова для поиска) «Project — Issue — Worklog»
При реконструкции будем использовать два принципа:
- Решаем поставленную задачу НИКАК не вовлекаясь в процессную философию, онтологию и пр. Наша задача — получить совпадение по показателям, все остальное — епархия консалтеров.
- Решаем поставленную задачу максимально простыми способами МИНИМАЛЬНО погружаясь в техническую специфику самого продукта. Только в объеме, необходимом и достаточном для исходной задачи.
Набор инструментов и материалов
Что достаем из чемоданчика на стол:
- Инстанс Jira.
- Помощь по Jira REST API.
- Postman для свободных экспериментов с запросами.
- Онлайн редактор JSON.
- jq онлайн песочница.
- jq Manual.
- R для написания скрипта.
Пишем скрипт
Положим, что у нас в Jira включена basic авторизация. Дальше будем использовать ее. Для работы с REST API будем использовать новый пакет httr2, который кроссплатформенный и многопоточный.
Просто решаем задачу, не фиксируясь на диалектах и объеме кода. Tidyverse неплох.
Достаем проекты
Тут все достаточно просто. можно получить список проектов «в лоб», есть специальное API Get all projects . Получили все проекты, выбрали интересующие.
resp <- base_req %>%
req_url_path_append("project") %>%
req_perform() %>%
resp_body_json() %>%
bind_rows() %>%
filter(stri_detect_fixed(name, "МОИ ПРОЕКТЫ")) %>%
distinct(self, id, key, name)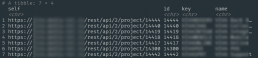
Достаем нужные Issues
Тут нас ожидает небольшая засада. Нет никакого API для того, чтобы получить список Issues, принадлежащих указанному проекту. Ну как то не завезли.
Ну и ладно. В Jira есть API для работы с поиском api/2/search. Тренируемся в web интерфейсе по проектной выборке, потом перетаскиваем в API запрос.
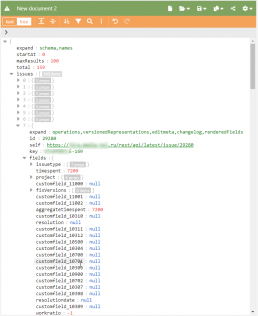
Тут нас опять поджидают опять пара засад. Первая — приходит муторный многоуровневый json со всяким хламом. Вторая — выдача выдается окном размером не более 1000 записей.
Первую засаду решим с помощью jq, вторую — либо положим, что у нас задач меньше в проекте и добавим ассерт, либо потом курсор добавим.
Оперировать в R или python вложенными списками нет ни малейшего желания. Для исследования и подбора магического jq преобразования пользуемся итеративно онлайн-песочницей и онлайн json редактором.
В ходе анализа находим в этом шлаке идентификатор спринта, на сей раз он оказался в поле customfield_10101. Не вдаемся в детали почему так, просто используем.
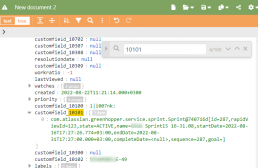
Получаем примерно такой код.
resp <- base_req %>%
req_url_path_append("search") %>%
req_url_query(jql = glue("project='{project_tag}'")) %>%
req_url_query(maxResults = 1000) %>%
req_perform()
resp_body <- resp_body_string(resp)
# убедимся, что количество записей меньше окна выдачи
jqr::jq(resp_body, '.total') %T>%
{flog.info(glue("Project '{project_tag}' has {.} issues"))} %>%
{assertInt(as.integer(.), upper = 1000)}
resp_body %>%
jqr::jq('[.issues[] | . + .fields | del(.fields) | {id, key,
issuetype:(.issuetype.name), is_subtask:(.issuetype.subtask), created,
status:.status.name, summary, sprint_raw:(.customfield_10101[]? // ""),
progress, project_name:(.project.name)}]') %>%
fromJSON()Достаем списания часов
Имеем список интересующих нас задач (Issues). Теперь надо по каждой вытащить worklog и определить списания часов в интересующем интервале. В текущей постановке интересовала полная трудоемкость, поэтому постфильтрация по дате не делается.
Опять для исследований итеративно используем сэмпл ответа + JSON Editor online + jq play, получаем магические формулы преобразований.
resp <- base_req %>%
req_url_path_append("issue") %>%
req_url_path_append(issue_tag) %>%
req_url_path_append("worklog") %>%
req_url_query(maxResults = 1000) %>%
req_perform()
resp_body <- resp_body_string(resp)
# убедимся, что количество записей меньше окна выдачи
crc_lst <- resp_body %>%
jqr::jq('{maxResults, total, get_all:(.maxResults == .total)}') %>%
fromJSON() %T>%
{flog.info(glue("Issue '{issue_tag}' has {.$total} records"))}
assertTRUE(crc_lst$get_all)
resp_body %>%
jqr::jq('[.worklogs[] | . + {author:.author.displayName} +
{updateAuthor:.updateAuthor.displayName}]') %>%
fromJSON()Постпроцессинг
Остались пустяки. Определиться с нужным концептом агрегации и требуемыми полями в выдаче, перевести в часы, провести агрегацию и сбросить в excel.
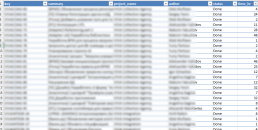
Дальнейшие модификации зависят от бизнес-требований и вашей фантазии. Единственно, не стоит превращать простой скрипт на один экран в мега-коннектор или продукт. Не стоит оно того, не стоит.